Продуктивність¶
Профілювання¶
Профілювання полягає в аналізі виконання програми та вимірюванні агрегованих даних. Ці дані можуть включати час, що минув для кожної функції, виконані SQL-запити…
Хоча профілювання саме по собі не покращує продуктивність програми, воно може виявитися дуже корисним для виявлення проблем із продуктивністю та визначення того, яка частина програми відповідає за них.
Odoo надає інтегрований інструмент профілювання, який дозволяє записувати всі виконані запити та відстеження стеку під час виконання. Його можна використовувати для профілювання як набору запитів користувацького сеансу, так і певної частини коду. Результати профілювання можна перевірити за допомогою вбудованого speedscope відкритого додатку, що дозволяє візуалізувати графік виконання, або проаналізувати за допомогою користувацьких інструментів, попередньо зберігши їх у JSON-файлі або в базі даних.
Увімкнути профайлер¶
Профілювальник можна ввімкнути або з інтерфейсу користувача, що є найпростішим способом, але дозволяє профілювати лише веб-запити, або з коду Python, що дозволяє профілювати будь-який фрагмент коду, включаючи тести.
Перед початком сеансу профілювання профайлер має бути глобально ввімкнений у базі даних. Це можна зробити двома способами:
Відкрийте інструменти режиму розробника, потім увімкніть кнопку Увімкнути профайлер. Майстер запропонує набір термінів дії для профілювання. Натисніть УВІМКНУТИ ПРОФАЙЛЕР, щоб увімкнути профайлер глобально.

Перейдіть до Налаштування –> Загальні налаштування –> Продуктивність та встановіть потрібний час у полі Увімкнути профайлер до.
Після увімкнення профайлера для бази даних, користувачі можуть увімкнути його для свого сеансу. Для цього знову натисніть кнопку Увімкнути профайлер у інструменти режиму розробника. За замовчуванням увімкнено рекомендовані опції Запис sql та Запис відстеження. Щоб дізнатися більше про різні опції, перейдіть до Collectors.
Коли профайлер увімкнено, всі запити, зроблені до сервера, профілюються та зберігаються в записі ir.profile. Такі записи групуються в поточний сеанс профілювання, який охоплює період з моменту ввімкнення профайлера до моменту його вимкнення.
Примітка
Бази даних Odoo Online не можуть бути профілювані.
Ручний запуск профайлера може бути зручним для профілювання певного методу або частини коду. Цей код може бути тестом, обчислювальним методом, повним завантаженням тощо.
Щоб запустити профайлер з коду Python, викличте його як контекстний менеджер. Ви можете вказати що ви хочете записати за допомогою параметрів. Для профілювання тестових класів доступний ярлик: self.profile(). Дивіться Collectors для отримання додаткової інформації про параметр collectors.
Example
with Profiler():
do_stuff()
Example
with Profiler(collectors=['sql', PeriodicCollector(interval=0.1)]):
do_stuff()
Example
with self.profile():
with self.assertQueryCount(__system__=1211):
do_stuff()
Примітка
Профілер викликається поза межами assertQueryCount для перехоплення запитів, зроблених під час виходу з менеджера контексту (наприклад, flush).
- class odoo.tools.profiler.Profiler[source]¶
Менеджер контексту, який використовується для початку запису деяких виконань. За замовчуванням зберігатиме відстеження стека SQL та асинхронних даних.
- __init__(collectors=None, db=Ellipsis, profile_session=None, description=None, disable_gc=False, params=None)[source]¶
- Параметри
db – Назва бази даних, яке буде використано для збереження результатів. За замовчуванням буде зроблено спробу автоматично визначити базу даних. Використовуйте значення
None, щоб не зберігати результати в базі даних.collectors – список рядків та об’єкт Collector Наприклад: [„sql“, PeriodicCollector(interval=0.2)]. Використовуйте
Noneдля collectors за замовчуваннямprofile_session – опис сеансу, який буде використано для повторного запуску кількох профілів. Використовуйте make_session(name) для формату за замовчуванням.
description – опис поточного профайлера. Пропозиція: (назва маршруту/метод тестування/модуль завантаження тощо)
disable_gc – прапорець для вимкнення gc під час профілювання (корисно для уникнення gc під час профілювання, особливо під час виконання sql)
params – параметри, що використовуються collectors (наприклад, інтервал кадру)
Коли профайлер увімкнено, всі виконання тестового методу профілюються і зберігаються у записі ir.profile. Такі записи групуються в один сеанс профілювання. Це особливо корисно при використанні декораторів @warmup та @users.
Порада
Аналіз результатів профілювання методу, який викликається декілька разів, може бути складним, оскільки всі виклики згруповано у відстеження стеку. Додайте контекст виконання як менеджер контексту, щоб розбити результати на декілька фреймів.
Example
for index in range(max_index):
with ExecutionContext(current_index=index): # Identify each call in speedscope results.
do_stuff()
Проаналізуйте результати¶
Щоб переглянути результати профілювання, переконайтеся, що профайлеп увімкнено глобально на базі даних, потім відкрийте інструменти режиму розробника і натисніть на кнопку у верхньому правому куті розділу профілювання. Відкриється вікно списку записів ir.profile, згрупованих за сеансом профілювання.
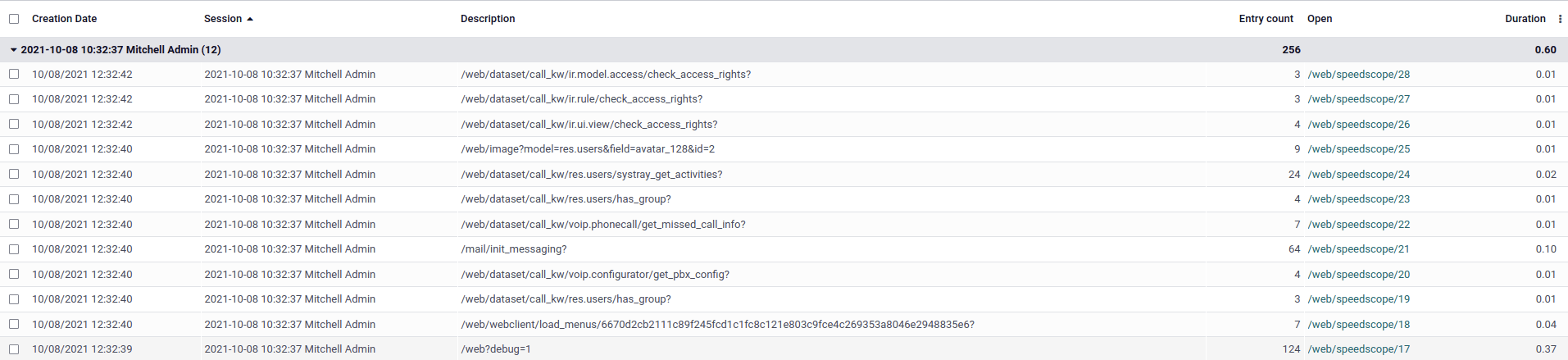
Кожен запис має посилання, яке можна клікнути, і яке відкриває результати speedscope в новій вкладці.
Speedscope виходить за рамки цієї документації, але є багато інструментів, які можна спробувати: пошук, виділення схожих кадрів, масштабування кадру, часова шкала, переважування лівого краю, сендвіч-вид…
Залежно від активованих опцій профайлера, Odoo генерує різні режими перегляду, до яких можна отримати доступ з верхнього меню.
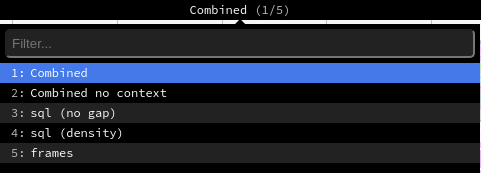
У режимі представлення Комбінований показано всі об’єднані SQL-запити та відстеження.
Представлення Комбіновано без контексту показує той самий результат, але ігнорує збережений контекст виконання <performance/profiling/enable>`.
Представлення sql (без пропусків) показує всі SQL-запити так, ніби вони виконувалися один за одним, без будь-якої логіки Python. Це корисно лише для оптимізації SQL.
У представленні sql (density) відображаються лише всі SQL-запити, залишаючи проміжки між ними. Це може бути корисним для визначення того, чи є проблема кодом SQL, чи Python, а також для визначення зон, у яких може бути об’єднано багато невеликих запитів.
У представленні кадри відображаються результати лише періодичний collector.
Важливо
Навіть попри те, що профайлер був розроблений якомога легшим, він все одно може впливати на продуктивність, особливо під час використання Синхронізація collector. Майте це на увазі під час аналізу результатів speedscope.
Collectors¶
У той час як профайлер займається тим, коли профілювання, collectors піклуються про що.
Кожен колектор спеціалізується на зборі даних профілювання у власному форматі та способі. Їх можна вмикати індивідуально з інтерфейсу користувача за допомогою спеціальної кнопки перемикача у інструменти режиму розробника, або з коду Python за допомогою ключа або класу.
Наразі в Odoo доступні чотири collectors:
Назва |
Кнопка перемикання |
Ключ Python |
Клас Python |
|---|---|---|---|
Запис sql |
|
|
|
Запис відстежень |
|
|
|
Запис qweb |
|
|
|
No |
|
|
За замовчуванням профайлер увімкнено collectors SQL та Періодичний. Обидва, коли він увімкнено з інтерфейсу користувача або коду Python.
SQL collector¶
Collector SQL зберігає всі SQL-запити, виконані до бази даних у поточному потоці (для всіх курсорів), а також відстеження стека. Накладні витрати collector додаються до аналізованого потоку для кожного запиту, а це означає, що його використання для великої кількості невеликих запитів може вплинути на час виконання та інші профайлери.
Це особливо корисно для налагодження кількості запитів або для додавання інформації до Періодичний collector у об’єднаному представленні speedscope.
Періодичний collector¶
Цей collector працює в окремому потоці та зберігає выдстеження стека аналізованого потоку через кожен інтервал. Інтервал (за замовчуванням 10 мс) можна визначити за допомогою опції Інтервал в інтерфейсі користувача або параметра interval у коді Python.
Попередження
Якщо інтервал встановлено на дуже низькому значенні, профілювання довгих запитів призведе до проблем з пам’яттю. Якщо інтервал встановлено на дуже високому значенні, інформація про короткі виконання функцій буде втрачена.
Це один з найкращих способів аналізу продуктивності, оскільки він повинен мати дуже незначний вплив на час виконання завдяки окремому потоку.
Колектор QWeb¶
Цей collector економить час виконання Python та запити до всіх директив. Що стосується SQL collector, накладні витрати можуть бути значними під час виконання великої кількості невеликих директив. Результати відрізняються від інших collectors з точки зору зібраних даних і можуть бути проаналізовані з форми ir.profile за допомогою спеціального віджета.
Це головним чином корисно для оптимізації представлень.
Ccollector синхронізації¶
Цей collector зберігає стек для кожного виклику та повернення функції та виконується в одному потоці, що значно впливає на продуктивність.
Це може бути корисним для налагодження та розуміння складних потоків, а також для відстеження їх виконання в коді. Однак це не рекомендується для аналізу продуктивності, оскільки накладні витрати високі.
Підводні камені продуктивності¶
Будьте обережні з випадковістю. Кілька виконань можуть призвести до різних результатів. Наприклад, collector сміття може бути запущений під час виконання.
Будьте обережні з блокуванням викликів. У деяких випадках зовнішній
c_callможе зайняти деякий час перед звільненням GIL, що призводить до неочікувано довгих кадрів з Періодичний collector. Це має бути виявлено профайлером і видати попередження. За потреби можна запустити профайлер вручну перед такими викликами.Зверніть увагу на кеш. Профілювання до того, як
view/assets/… знаходяться в кеші, може призвести до різних результатів.Зверніть увагу на накладні витрати профайлера. Накладні витрати SQL collector можуть бути значними, коли виконується багато невеликих запитів. Профілювання практичне для виявлення проблеми, але ви можете захотіти вимкнути профайлер, щоб виміряти реальний вплив зміни коду.
Результати профілювання можуть потребувати багато пам’яті. У деяких випадках (наприклад, профілювання встановлення або довгого запиту) можливо досягти ліміту пам’яті, особливо під час рендерингу результатів speedscope, що може призвести до помилки HTTP 500. У цьому випадку вам може знадобитися запустити сервер з вищим лімітом пам’яті:
--limit-memory-hard $((8*1024**3)).
Заповнення бази даних¶
Інтерфейс командного рядка Odoo пропонує функцію заповнення бази даних за допомогою команди командного рядка odoo-bin populate.
Замість стомлюючої ручної або програмної специфікації тестових даних можна використовувати цю функцію, щоб заповнити базу даних на вимогу бажаною кількістю тестових даних. Це можна використовувати для виявлення різноманітних помилок або проблем із продуктивністю в перевірених потоках.
Для заповнення заданої моделі можна визначити такі методи та атрибути.
- Model._populate_sizes¶
Повертає dict, що відображає символічні розміри (
'small','medium','large') на цілі числа, надаючи мінімальну кількість записів, яку має створити_populate().Стандартні розміри сукупності:
small: 10medium: 100large: 1000
- Model._populate_dependencies¶
Повернути список моделей, які потрібно заповнити перед поточною.
- Тип повернення
- Model._populate(size)[source]¶
Створіть записи для заповнення цієї моделі.
- Параметри
size (str) – символічний розмір для кількості записів:
'small','medium'або'large'
- Model._populate_factories()[source]¶
Генерує фабрику для різних полів моделі.
factory- це генератор значень (словник значень полів).Factory skeleton:
def generator(iterator, field_name, model_name): for counter, values in enumerate(iterator): # values.update(dict()) yield values
Дивіться
odoo.tools.populateдля отримання інформації про інструменти та додатків популяції.- Повертає
список пар(field_name, factory), де
фабрика- це функція-генератор.- Тип повернення
Примітка
Генератор відповідає за правильну обробку field_name. Генератор може генерувати значення для кількох полів одночасно. У цьому випадку field_name має бути радше «field_group» (повинно починатися з «_»), охоплюючи різні поля, оновлені генератором (наприклад, «_address» для генератора, який оновлює кілька полів адреси).
Примітка
Ви повинні визначити принаймні _populate() або _populate_factories() у моделі, щоб увімкнути заповнення бази даних.
Example
from odoo.tools import populate
class CustomModel(models.Model)
_inherit = "custom.some_model"
_populate_sizes = {"small": 100, "medium": 2000, "large": 10000}
_populate_dependencies = ["custom.some_other_model"]
def _populate_factories(self):
# Record ids of previously populated models are accessible in the registry
some_other_ids = self.env.registry.populated_models["custom.some_other_model"]
def get_some_field(values=None, random=None, **kwargs):
""" Choose a value for some_field depending on other fields values.
:param dict values:
:param random: seeded :class:`random.Random` object
"""
field_1 = values['field_1']
if field_1 in [value2, value3]:
return random.choice(some_field_values)
return False
return [
("field_1", populate.randomize([value1, value2, value3])),
("field_2", populate.randomize([value_a, value_b], [0.5, 0.5])),
("some_other_id", populate.randomize(some_other_ids)),
("some_field", populate.compute(get_some_field, seed="some_field")),
('active', populate.cartesian([True, False])),
]
def _populate(self, size):
records = super()._populate(size)
# If you want to update the generated records
# E.g setting the parent-child relationships
records.do_something()
return records
Інструменти наповнення¶
Для легкого створення необхідних генераторів даних доступно кілька інструментів для заповнення даних.
- odoo.tools.populate.randomize(vals, weights=None, seed=False, formatter=<function format_str>, counter_offset=0)[source]¶
Возвращает фабрику для итератора словарей значений с псевдослучайно выбранными значениями (среди
vals) для поля.- Параметри
- Повертає
функція виду (iterator, field_name, model_name) -> values
- Тип повернення
- odoo.tools.populate.cartesian(vals, weights=None, seed=False, formatter=<function format_str>, then=None)[source]¶
Возвращает фабрику для итератора словарей значений, которая объединяет все
valдля поля с другими значениями полей во входных данных.- Параметри
vals (list) – список, в якому буде вибрано значення залежно від
weightsweights (list) – список ймовірнісних ваг
seed – необов’язкова ініціалізація генератора випадкових чисел
formatter (function) – (val, counter, values) –> formatted_value
then (function) – если определено, фабрика будет использоваться после использования vals.
- Повертає
функція виду (iterator, field_name, model_name) -> values
- Тип повернення
- odoo.tools.populate.iterate(vals, weights=None, seed=False, formatter=<function format_str>, then=None)[source]¶
Возвращает фабрику для итератора словарей значений, который выбирает значение среди
valдля каждого входного значения. После того, как всеvalбудут использованы один раз, продолжить работу какthenили как генераторrandomize.- Параметри
vals (list) – список, в якому буде вибрано значення залежно від
weightsweights (list) – список ймовірнісних ваг
seed – необов’язкова ініціалізація генератора випадкових чисел
formatter (function) – (val, counter, values) –> formatted_value
then (function) – если определено, фабрика будет использоваться после использования vals.
- Повертає
функція виду (iterator, field_name, model_name) -> values
- Тип повернення
- odoo.tools.populate.constant(val, formatter=<function format_str>)[source]¶
Возвращает фабрику для итератора словарей значений, которая устанавливает поле в заданное значение в каждом входном словаре.
- odoo.tools.populate.compute(function, seed=None)[source]¶
Возвращает фабрику для итератора словарей значений, который вычисляет значение поля как
function(values, counter, random), гдеvalues- другие значения поля,counter- целое число, аrandom- генератор псевдослучайных чисел.
Належні практики¶
Пакетні операції¶
Під час роботи з наборами записів майже завжди краще виконувати пакетні операції.
Example
Не викликайте метод, який виконує SQL-запити, під час циклу по набору записів, оскільки він робитиме це для кожного запису набору.
def _compute_count(self):
for record in self:
domain = [('related_id', '=', record.id)]
record.count = other_model.search_count(domain)
Натомість замініть search_count на _read_group, щоб виконати один SQL-запит для всієї партії записів.
def _compute_count(self):
domain = [('related_id', 'in', self.ids)]
counts_data = other_model._read_group(domain, ['related_id'], ['__count'])
mapped_data = dict(counts_data)
for record in self:
record.count = mapped_data.get(record, 0)
Примітка
Цей приклад не є оптимальним і не є правильним у всіх випадках. Він є лише заміною для search_count. Іншим рішенням може бути попередня вибірка та підрахунок оберненого поля One2many.
Example
Не створюйте записи один за одним.
for name in ['foo', 'bar']:
model.create({'name': name})
Натомість, накопичуйте значення create та викличте метод create у пакеті. Це майже не впливає на результат і допомагає фреймворку оптимізувати обчислення полів.
create_values = []
for name in ['foo', 'bar']:
create_values.append({'name': name})
records = model.create(create_values)
Example
Не вдалося попередньо вибрати поля набору записів під час перегляду одного запису в циклі.
for record_id in record_ids:
model.browse(record_id)
record.foo # One query is executed per record.
Натомість спочатку перегляньте весь набір записів.
records = model.browse(record_ids)
for record in records:
record.foo # One query is executed for the entire recordset.
Ми можемо перевірити, чи записи попередньо завантажуються пакетно, прочитавши поле prefetch_ids, яке містить кожен ідентифікатор запису. Перегляд усіх записів разом є непрактичним,
При необходимости можно использовать метод with_prefetch для отключения пакетной предварительной выборки:
for values in values_list:
message = self.browse(values['id']).with_prefetch(self.ids)
Уменьшить алгоритмическую сложность¶
Алгоритмічна складність – це міра того, скільки часу знадобиться алгоритму для виконання з урахуванням розміру вхідних даних n. Коли складність висока, час виконання може швидко зростати зі збільшенням вхідних даних. У деяких випадках алгоритмічну складність можна зменшити, правильно підготувавши вхідні дані.
Example
Для заданої задачі розглянемо нативний алгоритм, створений з двома вкладеними циклами, складність якого дорівнює O(n²).
for record in self:
for result in results:
if results['id'] == record.id:
record.foo = results['foo']
break
Припускаючи, що всі результати мають різні ідентифікатори, ми можемо підготувати дані для зменшення складності.
mapped_result = {result['id']: result['foo'] for result in results}
for record in self:
record.foo = mapped_result.get(record.id)
Example
Вибір поганої структури даних для зберігання вхідних даних може призвести до квадратичної складності.
invalid_ids = self.search(domain).ids
for record in self:
if record.id in invalid_ids:
...
Якщо invalid_ids є структурою даних, подібною до списку, складність алгоритму може бути квадратичною.
Натомість, надайте перевагу використанню операцій з множинами, таких як перетворення invalid_ids на set.
invalid_ids = set(invalid_ids)
for record in self:
if record.id in invalid_ids:
...
Залежно від вхідних даних, також можна використовувати операції з наборами записів.
invalid_ids = self.search(domain)
for record in self - invalid_ids:
...
Використання індексів¶
Індекси баз даних можуть допомогти пришвидшити операції пошуку, як з пошуку в інтерфейсі користувача, так і через нього.
name = fields.Char(string="Name", index=True)
Попередження
Будьте обережні, щоб не індексувати кожне поле, оскільки індекси займають місце та впливають на продуктивність під час виконання однієї з команд INSERT, UPDATE або DELETE.